

1:综述
为什么学习数据分析
- 岗位需求
- python数据科学的基础
- 机器学习的课程基础
什么是数据分析
用适当的方法对收集的大量数据进行分析
帮助人们做出判断,以便采取适当的行动
jupyter notebook:
Python笔记软件
2:Matplotlib
将数据可视化,更直观的呈现
使数据更加客观、更具说服力
最流行的python底层绘图库,主要做数据可视化,模仿matlab构建
1 | from matplotlib import pyplot as plt #导入pyplot |
目前存在的问题:
- 图片大小
- 保存到本地
- 描述信息,比如x,y轴表示什么
- 刻度
- 线条样式
- 标记特殊点
2.1 设置图片大小-figure
1 | fig = plt.figure(figsize=(20,8),dpi=80) |
2.2 设置x,y轴步长-xticks/yticks
1 | plt.xticks(x) #设置步长 |
上述绘图,无法显示中文
2.3 加入中文字体支持-FontProperties
方法1:
1 | import matplotlib |
方法2:
1 | from matplotlib import font_manager |
2.4 加入描述信息-xlabel/ylabel/title
1 | plt.xlabel("时间",fontproperties=my_font) |
2.5 设置网格-grid
1 | plt.grid() |
2.6 绘制两个图形-legend
1 | plt.plot(x,y1,label="自己",color="orange",linestyle=":") |
color=’r’ 颜色
linestyle=’–’ 线条风格:-实线;–虚线;-.点划线;:点虚线;留空或空格,表示无线条
linewidth=5 线粗细
alpha=0.4 透明度
2.7 绘制散点图-scatter
1 | plt.scatter(x, y) |
2.8 绘制柱状图-bar
1 | #绘制电影与其对应票房 |
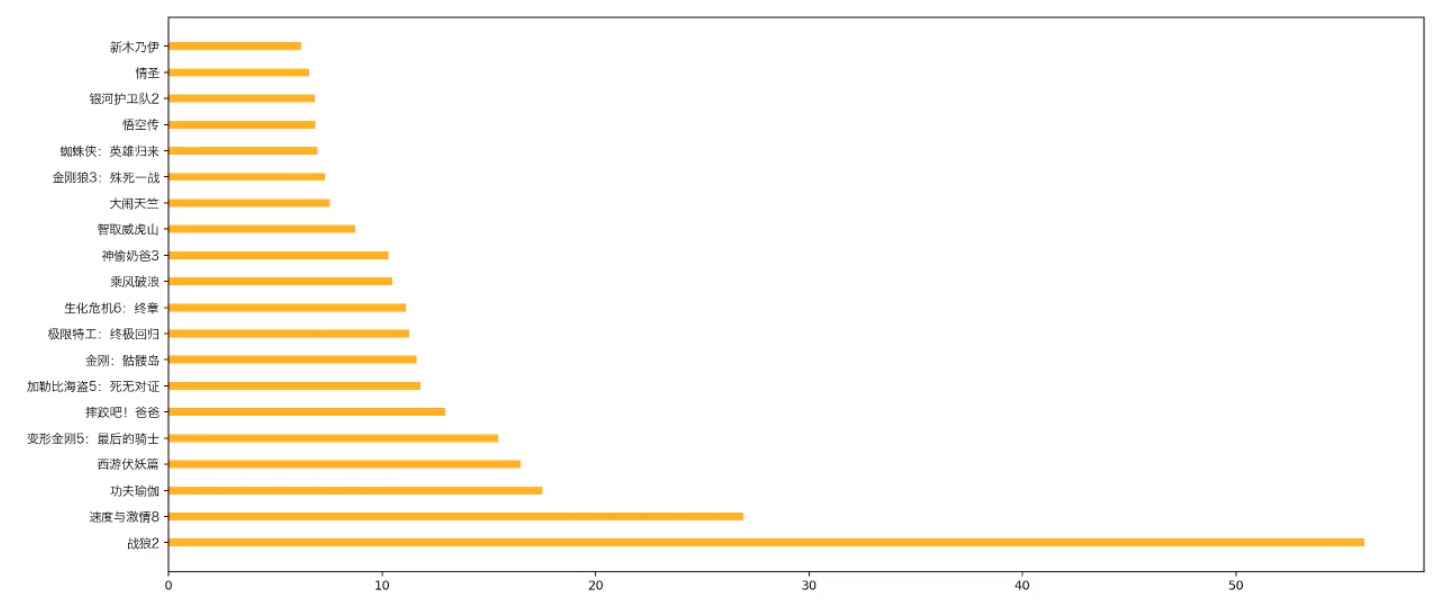
2.9 绘制条形图-barh
1 | plt.barh(range(len(a)),b,height=0.3,color='orange') |
2.10 绘制直方图-hist
有250部电影的时长,统计时长分布的数量,比如100到120分钟的电影数。
组数=极差/组距。
1 | a = [120,76,124,161……] #250部电影的时长。 |
当(最大值-最小值)/假定组距 无法除尽时,根据假定组距绘制的x刻度会偏移。
2.11 绘制其他图形
https://matplotlib.org/gallery/index.html
前端画图库js——echarts:
https://echarts.apache.org/examples/zh/index.html
图表代码托管——Plotly:
https://plot.ly/python
2:Numpy
什么时numpy?
一个再python中做科学计算的基础库,重在数值计算,也是大部分python科学计算库的基础库,多用于在大型、多维数组上执行数值计算。
2.1 创建数组:
1 | import numpy as np |
结果:
[1 2 3]
<class ‘nmpy.ndarray’>
2.2 数据类型
1 | d = np.array(range(1,4),dtype="float32") #dtype指定数组中数据的数据类型 |
修改浮点型的小数位数
1 | a = np.array(random.random() for i in range(10)) |
2.3 数组形状
1 | t1 = np.array([[1,2,3],[3,4,5]]) |
数组的形状
1 | t2 = np.arange(12) #新建一维数组 |
2.4 数组计算
数组和数
1 | t6 = np.arange(24) |
数组和数组
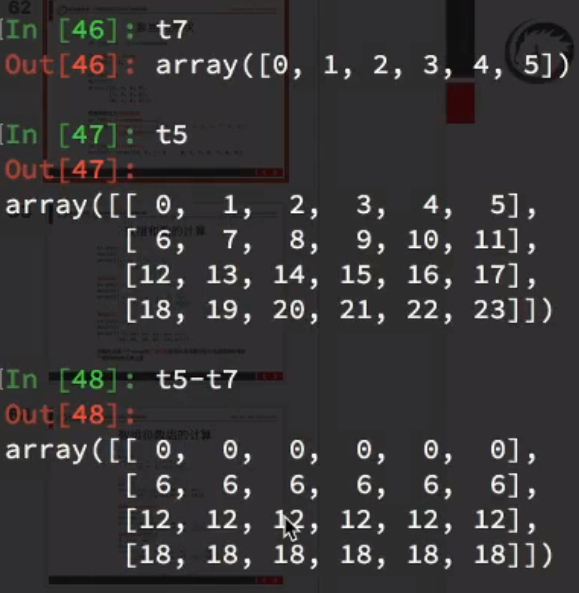
形状相同:(4,6)与(4,6)
1 | t8 = np.arange(100,124).reshape(4,6) |
(4,6)与(,6)
(4,6)与(4,1)
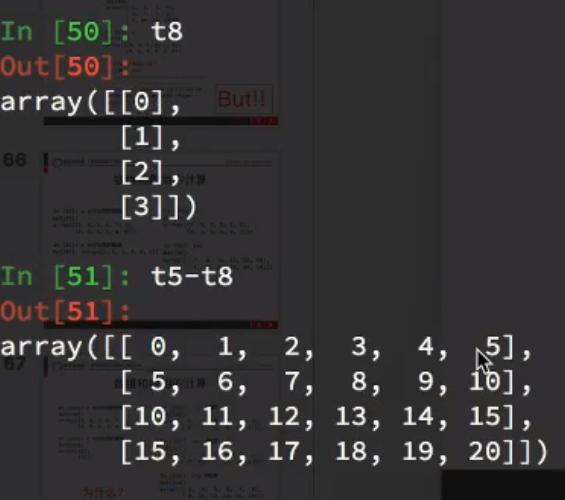
广播原则:
如果两个数组的后缘维度,即从末尾开始算起的维度的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和或长度为1的维度上进行
2.5 读取数据
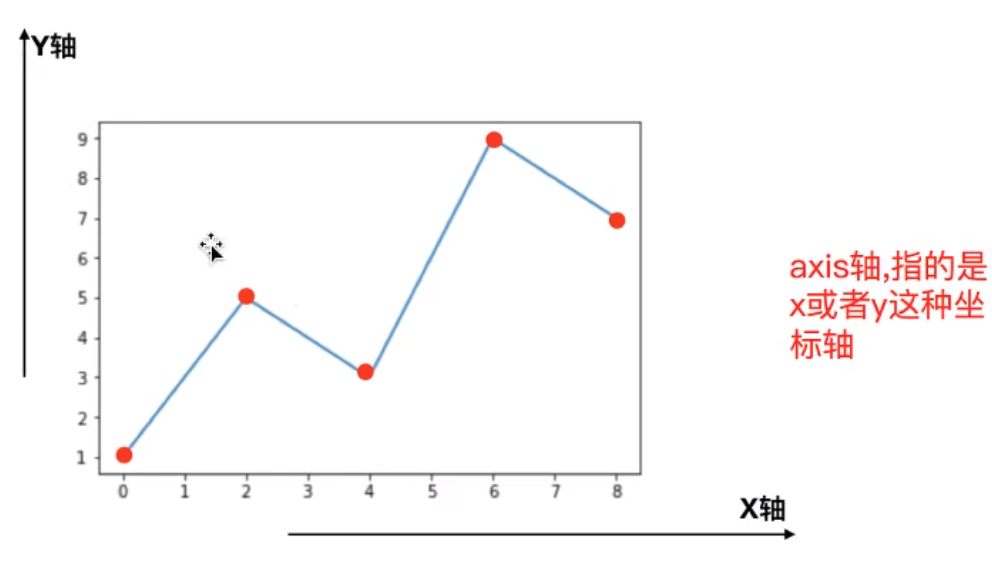
轴
一维数组只有一个轴,即0轴
二维数组有两个轴,0和1轴。(2,5),2是0轴长度,5是1轴长度
三维数组有三个轴,0,1,2轴
读取数据
1 | np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False) |
frame:文件、字符串或产生器
dtype:数据类型
dlimiter:分割字符串,默认是空格
skiprows:跳过前x行
usecols:读取指定的列
unpack:True表示,读入属性将分别写入不同的数组变量,False 读入数据只写入一个数组变量,默认False。转置效果。
读取的文件内容格式:
1 | 1241,1241,15346,2451 |
读取时可以按,分割。按行划分
2.6 矩阵转置
1 | t2.transpose() |
2.7 索引和切片
取第二行:
1 | t2[2] |
取连续的多行:
1 | t2[2:] |
取不连续的多行:
1 | t2[[2,8,10]] |
取第一列:
1 | t2[:,0] |
取连续多列:
1 | t2[:,2:] |
取不连续的多列:
1 | t2[:,[0,2,5]] |
取3行四列的值:
1 | t2[3,4] |
取多行多列:3行到5行,2列到4列,因为:左右是左闭右开区间,行数为索引+1
1 | t2[2:5,1:4] |
取多个不连续的点:(0,0) (2,1) (5,5)
1 | t2[[0,2,5],[0,1,5]] |
2.8 修改数值
1 | t[:,2:4] = 0 |
布尔索引
1 | t2<10 #相同的矩阵,矩阵值为布尔类型,对应位置满足值小于10,则为1,否则为0 |
三元运算符
1 | np.where(t<10,0,10) #如果小于10,替换为0,否则替换为10 |
裁剪
1 | t.clip(10,18) #小于10的替换为10,大于18的替换为18 |
1 | t2 = t2.astype(float) |
2.9 拼接数组
1 | np.vstack(t1,t2) #竖直拼接 |

2.10 行列交换
行交换:
1 | t[[1,2],:] = t[[2,1],:] |
列交换:
1 | t[:,[0,2]] = t[:,[2,0]] |
2.11 其他方法
1 | #获取最大最小值 |
2.12 生成随机数
1 | np.random.rand(3,4) #均匀分布 |
种子:
1 | np.random.seed(10) |
2.13 copy和view
- a=b完全不复制,a和b相互影响。
- a = b[:],视图操作,创建新对象a,但a的数据完全由b保管,两者数据变化一致。
- a = b.copy()复制,a和b互不影响。
2.14 nan和inf
nan(NAN,Nan):not a number表示不是一个数字
inf(-inf,inf):infinity,正无穷,-inf表示负无穷
一个数字除以0,python中会报错,numpy中是一个inf
nan:
- 两个nan不相等
1 | np.nan !=np.nan |
- 计算nan个数
1 | np.count_nonzero(t2!=t2) #t2!=t2,得到新矩阵,每个位置是bool类型,true表示该位置是nan |
- 计算矩阵和
1 | np.sum(t3) |
2.15 常用统计函数
求和:t.sum(axis=0)
均值:t.mean(axis=0)
中值:t.median(axis)
最大值:t.max
最小值:t.min
极值:np.ptp(t,axis=None) 最大值和最小值之差
标准差:t.std(axis=None)
默认返回多维数组的全部统计结果

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.sci.ci/2020/09/29/Python%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/