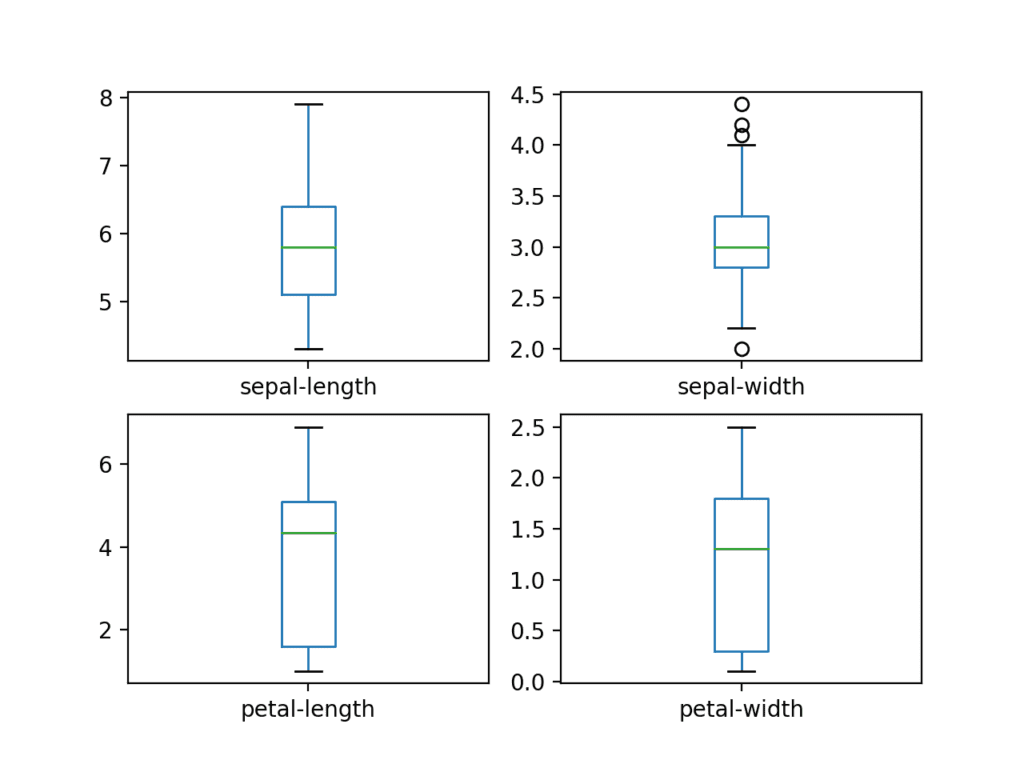
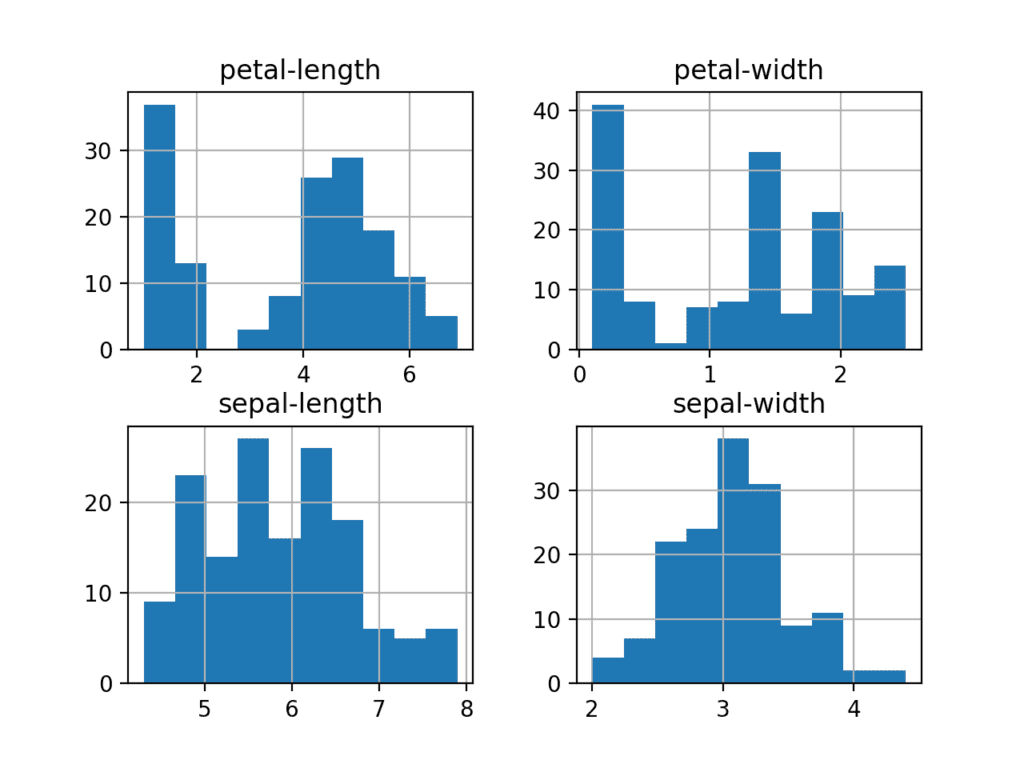
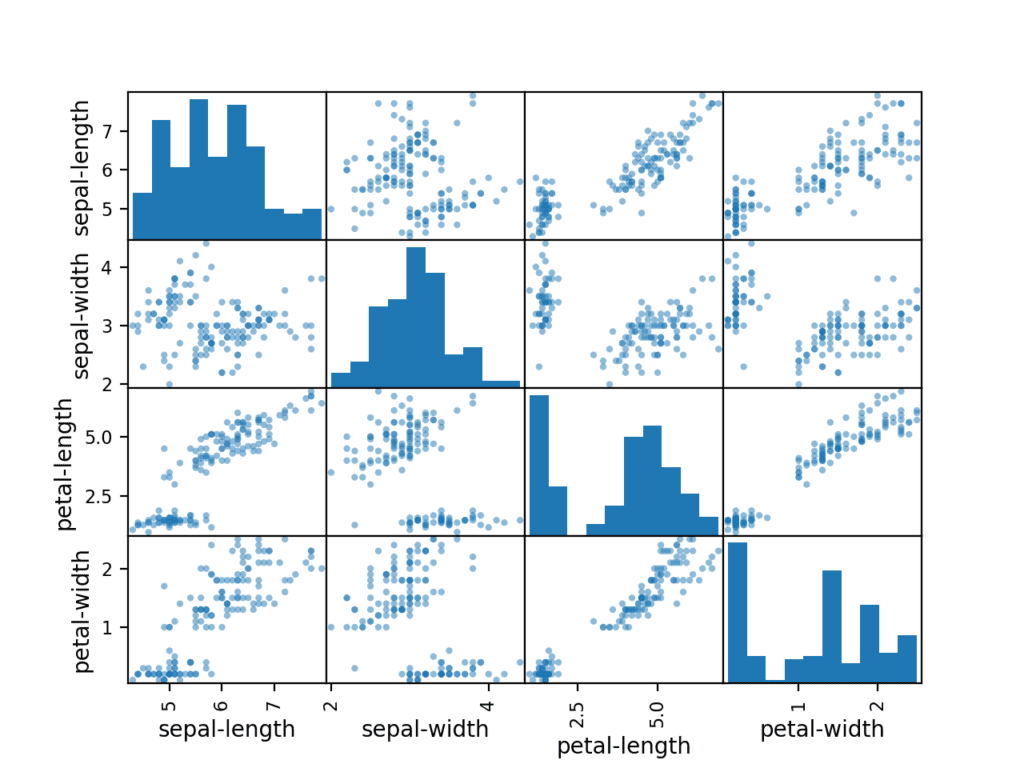
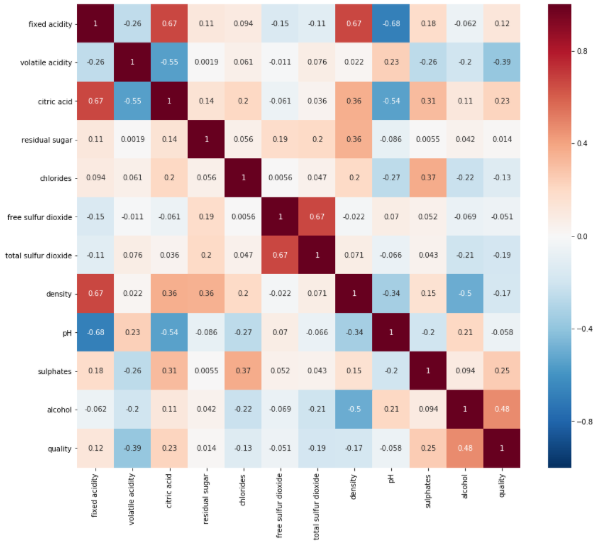
import matplotlib.pyplot as plt import seaborn as sns # dataset is dataframe correlation = dataset.corr() # display(correlation) plt.figure(figsize=(14, 12)) heatmap = sns.heatmap(correlation, annot=True, linewidths=0, vmin=-1, cmap="RdBu_r")
1.2.3. 两个变量之间的对比
1 2 3 4 5 6 7 8 9 10 11 12 13
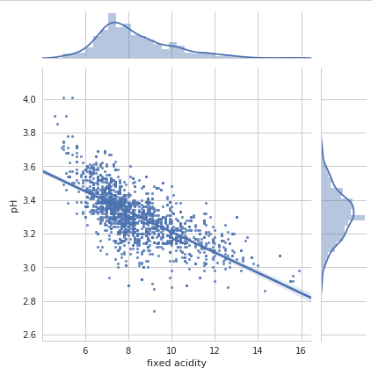
#Visualize the co-relation between pH and fixed Acidity
#Create a new dataframe containing only pH and fixed acidity columns to visualize their co-relations fixedAcidity_pH = dataset[['pH', 'fixed acidity']]
#Initialize a joint-grid with the dataframe, using seaborn library gridA = sns.JointGrid(x="fixed acidity", y="pH", data=fixedAcidity_pH, size=6)
#Draws a regression plot in the grid gridA = gridA.plot_joint(sns.regplot, scatter_kws={"s": 10})
#Draws a distribution plot in the same grid gridA = gridA.plot_marginals(sns.distplot)
2. 模型选择
sklearn提许多模型,对于不同的数据集,不同的模型训练之后会产生不同的结果。
常用的模型和导入方式
1 2 3 4 5 6 7
from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC